

Photo by Viktor Talashuk on Unsplash
Semantic Search With Vector Embedding
Semantic Search with C# and Atlas Vector Search


Traditionally, searching for a concept in a text involves identifying keywords and matching them with some user input.
Semantic search provides a different approach. It tries to establish relationships between the meanings of words.
With the rise in popularity of RAG as a technique to use customers' specific data with LLMs, embeddings are gaining popularity in many areas.
This article is using C# and Atlas Vector Search. Nonetheless, many other vector databases provide similar features, accessible from all the major programming languages.
Embeddings
Embeddings are a numerical representation of information. This can be a written text, an image, an audio file, and a video.
Translated to numbers (into multi-dimensional vectors), they can be used by the machine to understand real-world concepts.
Compared to the traditional feature embedding practice from LM, in which the output is generally a big matrix. Having to deal with a single vector is way less demanding. This is without risk of information loss.
Refer to this article from AWS for a better explanation of this concept.
The task of comparing if two texts are semantically similar becomes something that the machine can perform quite well without the need for special hardware.
At the time of writing this article, the top three used techniques to measure similarities between embeddings are:
Euclidian distance: takes into account all the dimensions of the vector.
Cosine similarity: use for semantic similarity and, in general, it is not relevant how often a term appears in the text.
dotProduct: is similar to cosine similarity but takes also into account the frequency of the terms
Here is a better explanation.
Embeddings in DotNet
In C# there are a couple of different ways to distil written text into vectors.
Many different libraries solve this problem. Also, OpenAI's API has a dedicated endpoint.
The example in this article uses Local Embeddings from Microsoft.
The library wraps the interaction with embedding models and is built to simplify semantic search in a local environment.
Add the package reference to the project
dotnet add the package SmartComponents.LocalEmbeddings
This package is currently part of the SmartComponent repository. However, in the future, this might change. It will probably be moved to SemanticKernel.
Here is the C# code to generate the embeddings from a text.
using var embedder = new LocalEmbedder();
var embedded = embedder.Embed("artificial intelligence");
This will generate a 384-dimensional embedding vector. Each dimension is a 4-byte single precision float.
Using quantization, the size can be shrunk.
Store into MongoDB
This part is no different from any other insert into a MongoDB collection.
It is important to consider also storing some information alongside the embedding.
Once the retrieval of the similar embedding happens, the entity will also contain the data that generated the vector, avoiding the need to perform further queries.
When storing information about a book it is possible to do something similar to the following.
var booksVectorsCollection = conn
.GetDatabase("BooksDb")
.GetCollection<BookVector>("books-vector");
var embedded = books.Select(b => new BookVector
(
b.Id,
b.Title,
b.SubTitle,
b.Authors,
b.Description,
b.Categories,
embedder.Embed($"Title: {b.Title} ### Subtitle: {b.SubTitle} ### Categories: {ParseCategories(b.Categories)} ### Description: {b.Description}")
));
await booksVectorsCollection.InsertManyAsync(embedded);
At this point, the MongoDB collection will have a shape similar to
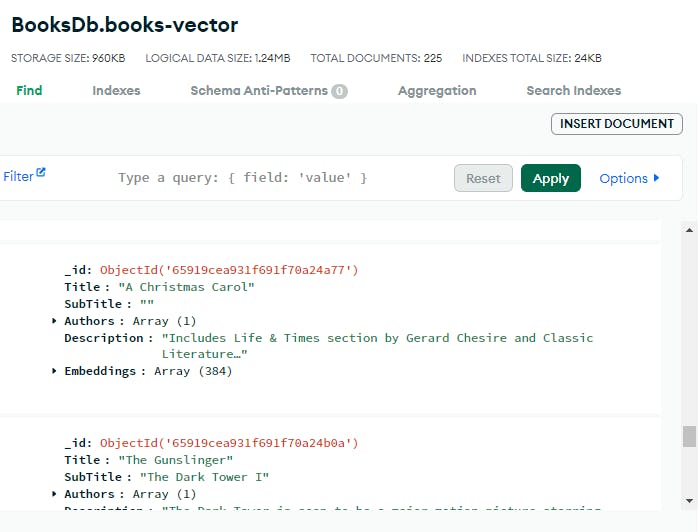
Atlas Vector Search
Now that the data is stored in the MongoDB collection, it is possible to create an Atlas Search Vector index to leverage Atlas Search for embedding-based similarity search.
At the time of writing this article, the UI for this feature on Atlas is:
The Atlas Vector Search section is in the Atlas Search tab.
To create the vector index, this is the required configuration
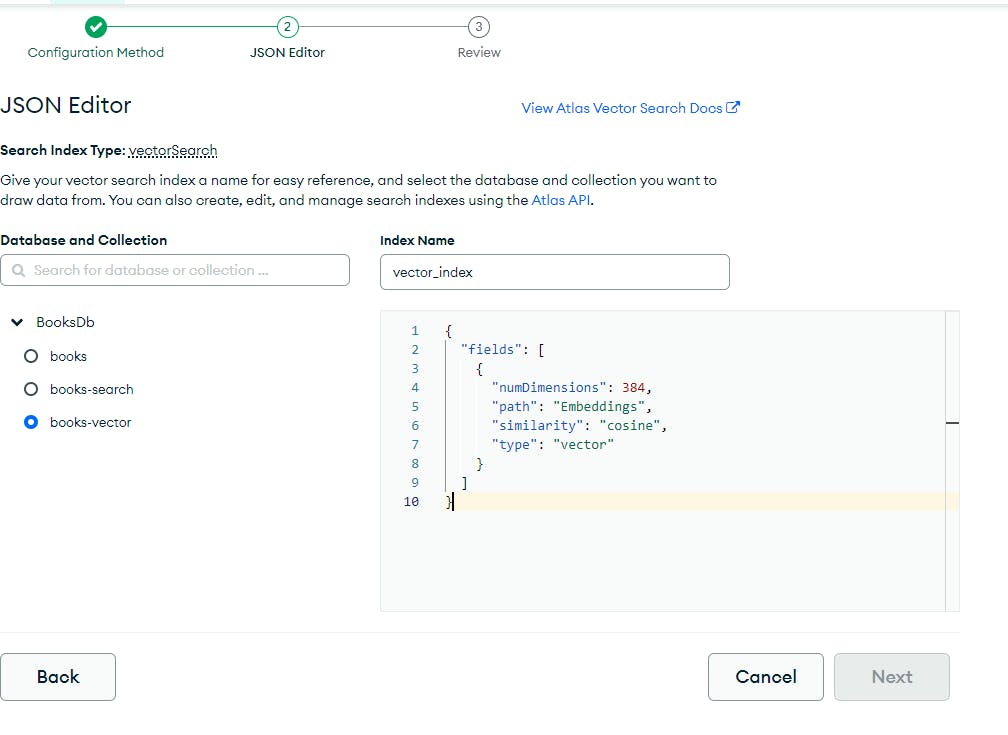
On the left side, there is the three to pick the collection that contains the embeddings.
On the right side, there is the JSON input to provide the configuration for the embedding.
numDimensions must match the dimension of the generated vectors. So it depends on the model used for the embedding. In this case, it is 384.
path is the path to the property that stores the embeddings
similarity is the algorithm that will be used to compute the similarity search. This means that the index is built to work with this specific algorithm to solve this type of search.
It is possible to provide filters and additional configurations for specific use cases. Here is the link to the documentation.
Once the index is created, it is possible to run a semantic search on the collection's items.
Search
Performing a search on the MongoDB collection is not different from running a query.
However, the search parameter is not a text but a vector.
This because the index does not know what is the algorithm that was used to generate the embeddings that are in the collection, it only knows how to compare them.
Before running the search, it is necessary to generate the embeddings for the text used as input and pass them into the queryVector parameter.
Using C# and MongoDB Driver and the same library that was used to generate the embeddings, the steps are the following:
Generate embeddings for the search that we want to (semantic) search.
var searchText = "artificial intelligence"; using var embedder = new LocalEmbedder(); var target = embedder.Embed(searchText);Configure the options to specify:
IndexName: the name of the index to use
NumberOfCandidates: the number of nearest neighbours to consider during the search
Filter: a filter. This is optional.var options = new VectorSearchOptions<BookVector>() { IndexName = "vector_index", NumberOfCandidates = 15, // Filter = ... };Build the aggregation
await booksVectorsCollection .Aggregate() .VectorSearch( m => m.Embeddings, // embedding field target.Values, limit: 5, options ).ToListAsync();Note that the
limitparameter is the number of documents that will be returned by the quey. This cannot exceed the number of candidates specified in theoptions.
The result of this operation is the semantic search on the items in the collection.
Considerations
Storing Embeddings
It is very likely that when adding Atlas Vector Search to an existing application. There is already a data storage populated with all the information for the search. These can be in a database, not necessarily on a MongoDB collection.
Even if they were in MongoDB, they could be scattered in many separate collections, each belonging to a different domain.
In these scenarios, the initial generation of the index will be a one-shot task. Then, there will probably be an asynchronous process that updates and refreshes the embeddings.
A suggestion is to store the information used to generate the embeddings, in the same entity with the vector.
This way, the search result will already contain the relevant information to provide to the end user. Furthermore, it will make it easier to update or delete existing entities.
If the data storage is already a MongoDB collection in Atlas, then it is possible to use Database Triggers and invoke an Atlas Function. The function will contain the logic to generate and store the embeddings.
The generation of the vector, depending on the LLM, the precision, and other factors can require even seconds. This should be a separate process that won't keep the user waiting for it to finish.
Then, in an eventually consistent fashion, the data will be available for semantic search.
Precision
It is important to understand the type of problem at hand.
Many embeddings are encoded in float32 and the dimension of the vector can vary quite a bit.
Of course, with many dimensions, the search will produce a result closer to the one expected.
However, this will require more storage, RAM, and CPU/GPU for the computation and the similarity operation.
It is suggested to use quantization, which will produce a less precise but still good enough output.
This and the selection of the information to use to generate the embedding are part of the initial set of tests that must be done to achieve a good result.